模式切换
Set 集合
Set 接口
Set 接口继承 Collection,特点:
- 元素无序
- 元素唯一
Set 的实现类:
| 实现类 | 底层数据结构 | 线程安全性 | 适用场景 |
|---|---|---|---|
HashSet | HashMap | 非线程安全 | 快速存取、不关心顺序 |
TreeSet | 红黑树 | 非线程安全 | 自动排序 |
LinkedHashSet | LinkedHashMap | 非线程安全 | 维护插入顺序 |
HashSet
HashSet 实现了 Set 接口,不允许存储重复的元素,并且不保证元素的存储顺序。HashSet 的底层数据结构和逻辑设计非常高效,使其适用于需要快速插入、删除和查找操作的场景。
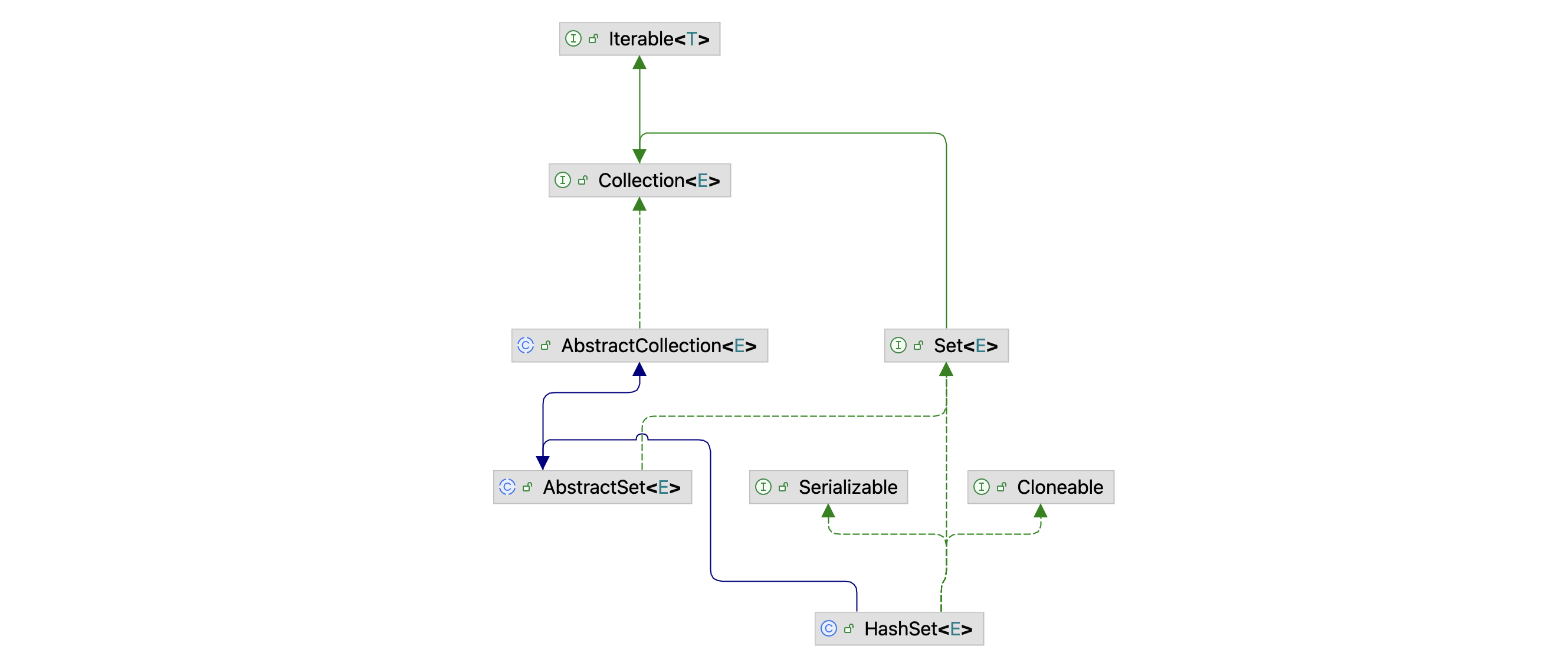
图 HashSet 类的继承关系
数据结构
HashSet 的底层数据结构主要基于 HashMap 实现。具体来说,HashSet 内部维护了一个 HashMap 实例,其中:
- 键(Key):HashSet 中的元素存储在 HashMap 的键部分。java
private transient HashMap<E,Object> map; - 值(Value):HashMap 的值部分是一个固定的对象,通常是一个私有的静态常量(例如,在 Java 的实现中,这个常量名为 PRESENT)。由于 HashSet 只关心键部分,值部分并不存储实际的数据。java
// 与后置映射中的对象关联的虚拟值 private static final Object PRESENT = new Object();

图 HashSet 类中所有的属性
HashMap 的底层数据结构是一个数组 + 链表(或红黑树)的组合:
- 数组:HashMap 使用一个数组来存储桶(Bucket),每个桶用于存储元素的链表或红黑树。
- 链表/红黑树:当多个元素哈希到同一个桶时,它们会以链表的形式存储。在 Java 8 及以后的版本中,如果链表的长度超过一定阈值(默认为 8),并且数组的长度大于等于 64,链表会转换为红黑树,以提高查找性能。
构造方法
HashSet 提供了五个构造方法,如下图所示:
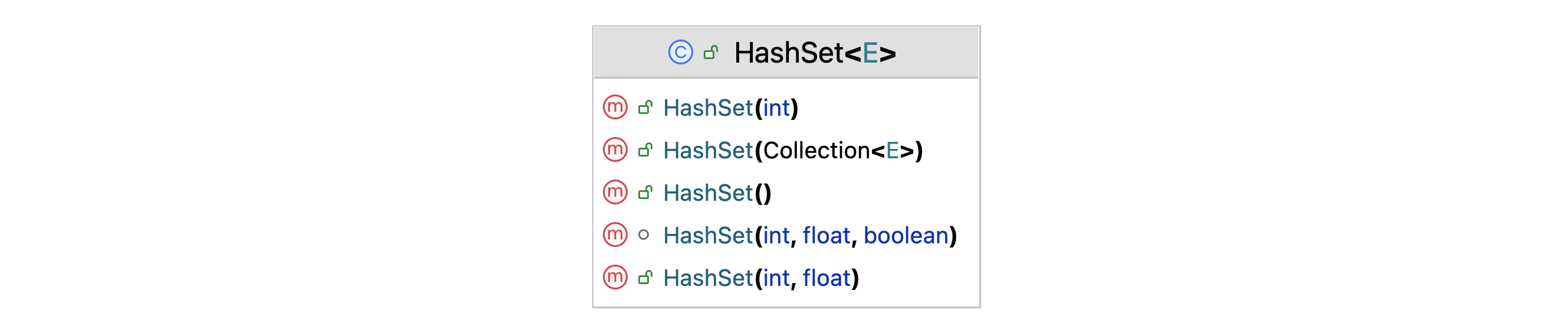
图 HashSet 类中提供的构造方法
HashSet():无参构造方法。创建一个空的 HashSet 实例,初始容量为 16,加载因子为 0.75。javapublic HashSet() { map = new HashMap<>(); }HashSet(Collection<? extends E> c):基于现有集合创建。将传入的集合 c 转换为 HashMap 的键集合。java/** * 构造一个包含指定集合中的元素的新集合。HashMap 是用默认负载因子(0.75)创建的,初始容量足以包含指定集合中的元素。 * * @param c 要将其元素放入此集合的集合 * @throws NullPointerException 如果指定的集合为空 */ public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); }HashSet(int initialCapacity, float loadFactor):指定初始容量和加载因子的构造方法。创建一个空的 HashSet 实例,初始容量为initialCapacity,加载因子为loadFactor。java/** * 构造一个新的空集合;HashMap 实例具有指定的初始容量和指定的负载因子。 * * @param initialCapacity 哈希映射的初始容量 * @param loadFactor 哈希映射的负载因子 * @throws IllegalArgumentException 如果初始容量小于零,或者负载系数是非正的 */ public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); }HashSet(int initialCapacity):指定初始容量的构造方法。创建一个空的 HashSet 实例,初始容量为initialCapacity,加载因子为 0.75。java/** * 构造一个新的空集合;HashMap 实例具有指定的初始容量和默认的负载因子(0.75)。 * * @param initialCapacity 哈希映射的初始容量 * @throws IllegalArgumentException 如果初始容量小于零 */ public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); }HashSet(int initialCapacity, float loadFactor, boolean dummy):用于 LinkedHashSet 的构造方法,创建一个空的 HashSet 实例,初始容量为initialCapacity,加载因子为loadFactor。java/** * 构造一个新的空链接散列集。(这个包私有构造函数只被 LinkedHashSet 使用)支持的 HashMap 实例是一个 LinkedHashMap,具有指定的初始容量和指定的负载因子。 * * @param initialCapacity 哈希映射的初始容量 * @param loadFactor 哈希映射的负载因子 * @param dummy 忽略(将此构造函数与其他 int,float 构造函数区分开来。) * @throws IllegalArgumentException 如果初始容量小于零,或者负载系数是非正的 */ HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }
添加元素
当向 HashSet 添加一个元素时,实际调用的是 HashMap 的 put(K key, V value) 方法。
java
/**
* 如果指定元素不存在,则将该元素添加到此集合。
* 更正式地说,如果此集合不包含元素 e2,则将指定的元素 e 添加到此集合,例如:e == null ? e2 == null : e.equals(e2)。
* 如果该集合已经包含该元素,则调用保持该集合不变并返回 false。
*
* @param e 要添加到此集合的元素
* @return true 如果此集合尚未包含指定的元素
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}HashMap 的 put(K key, V value) 方法如下:
java
/**
* 将指定值与此映射中的指定键关联。
* 如果映射以前包含键的映射,则替换旧值。
*
* @param key 要与指定值相关联的键
* @param value 值,以便与指定的键关联
* @return 与 key 关联的前一个值,如果没有 key 的映射,则为空(null 返回也可以表明映射先前将 null 与 key 关联)。
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}在该方法的定义中调用 hash(Object key) 方法计算哈希值:
java
/**
* 返回哈希码 h 的散列值。这个散列值必须与 HashMap 类的 hash 方法一致。
*
* @param key 键
* @return h 的散列值
*/
static final int hash(Object key) {
int h;
// 如果 key 为 null,则哈希值为 0;否则,哈希值为 key 的 hashCode() 方法返回值的异或操作。
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // h >>> 16 是为了增加哈希值的随机性
}putVal() 方法中实现了 HashMap 的添加元素逻辑:
- 确定桶位置:根据哈希值和数组的长度,使用位运算 (数组长度 - 1) & 哈希值 确定元素应该存储在哪个桶中。
- 处理冲突:
- 如果桶中为空,直接将元素添加到桶中。
- 如果桶中已有元素,依次比较桶中元素的哈希值和
equals()方法: - 如果找到哈希值和
equals()方法都相等的元素,说明元素已存在,添加操作失败。 - 否则,将新元素添加到链表的末尾(或红黑树中)。
java
/**
* 实现 Map.put 和相关方法。
*
* @param hash 键的散列值
* @param key 键
* @param value 值
* @param onlyIfAbsent 如果为 true,则不更改现有值
* @param evict 如果为 false,表处于创建模式。
* @return 前一个值,如果没有则为空
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // 键的现有映射
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}删除元素
删除元素的过程与添加元素类似:
java
/**
* 如果指定元素存在,则从该集合中删除指定元素。
* 更正式地,如果这个集合包含这样一个符合条件的元素 o == null ? e == null : o.equals(e),则移除这个元素。
* 如果此集合包含该元素,则返回 true(或者等价地,如果此集合因调用而更改),一旦调用返回,这个集合将不包含该元素。
*
* @param o 对象,如果存在,则从该集合中删除
* @return true 如果集合包含指定的元素
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}实际调用的是 HashMap 的 remove(Object key) 方法:
hash(key)计算哈希值:调用元素的hashCode()方法,计算其哈希值。
java
/**
* 从此映射中删除指定键的映射(如果存在)。
*
* @param key 要从映射中删除其映射的键
* @return 与 key 关联的前一个值,如果没有 key 的映射,则为空(null 返回也可以表明映射先前将 null 与 key 关联)。
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}removeNode() 方法的具体实现如下:
- 确定桶位置:根据哈希值和数组的长度,确定元素所在的桶。
- 遍历桶:遍历桶中的链表或红黑树,找到要删除的元素。
- 删除元素:从链表或红黑树中移除该元素。
java
/**
* 实现 Map.remove 和相关方法
*
* @param hash 键的哈希值
* @param key 键
* @param value 值,如果不匹配,则不删除
* @param matchValue 如果为 true,只删除其值相等的部分
* @param movable 如果为 false,则在删除时不要移动其他节点
* @return 节点,如果没有则为空
*/
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}总结
当 HashMap 中的元素数量超过其容量(即桶的数量)和加载因子(默认为 0.75)的乘积时,HashMap 会进行扩容。扩容过程如下:
- 创建新数组:创建一个新的数组,其容量为原数组容量的两倍。
- 重新哈希:遍历原数组中的每个桶,将桶中的元素重新哈希,并放入新数组的相应位置。
- 扩容机制保证了 HashMap 在元素数量增长时,仍能保持较高的查找效率。
在使用 HashSet 时,需要注意以下几点:
- 重写
hashCode()和equals()方法:对于自定义对象,需要重写hashCode()和equals()方法,以确保哈希值的正确计算和元素的正确比较。 - 处理
null值:HashSet 允许存储null值,但最多只能存储一个null值(因为null的哈希值是固定的)。 - 线程安全:如果需要在多线程环境下使用 HashSet,可以使用
Collections.synchronizedSet()方法创建一个同步的 Set,或者使用 ConcurrentHashMap 实现的CopyOnWriteArraySet等线程安全的集合类。
TreeSet
TreeSet 实现了 NavigableSet 接口,是一个有序的、不允许有重复元素的集合。TreeSet 的底层数据结构是基于红黑树(Red-Black Tree)实现的。红黑树是一种自平衡的二叉查找树,能够在动态数据结构中维持排序和二分搜索的性能。
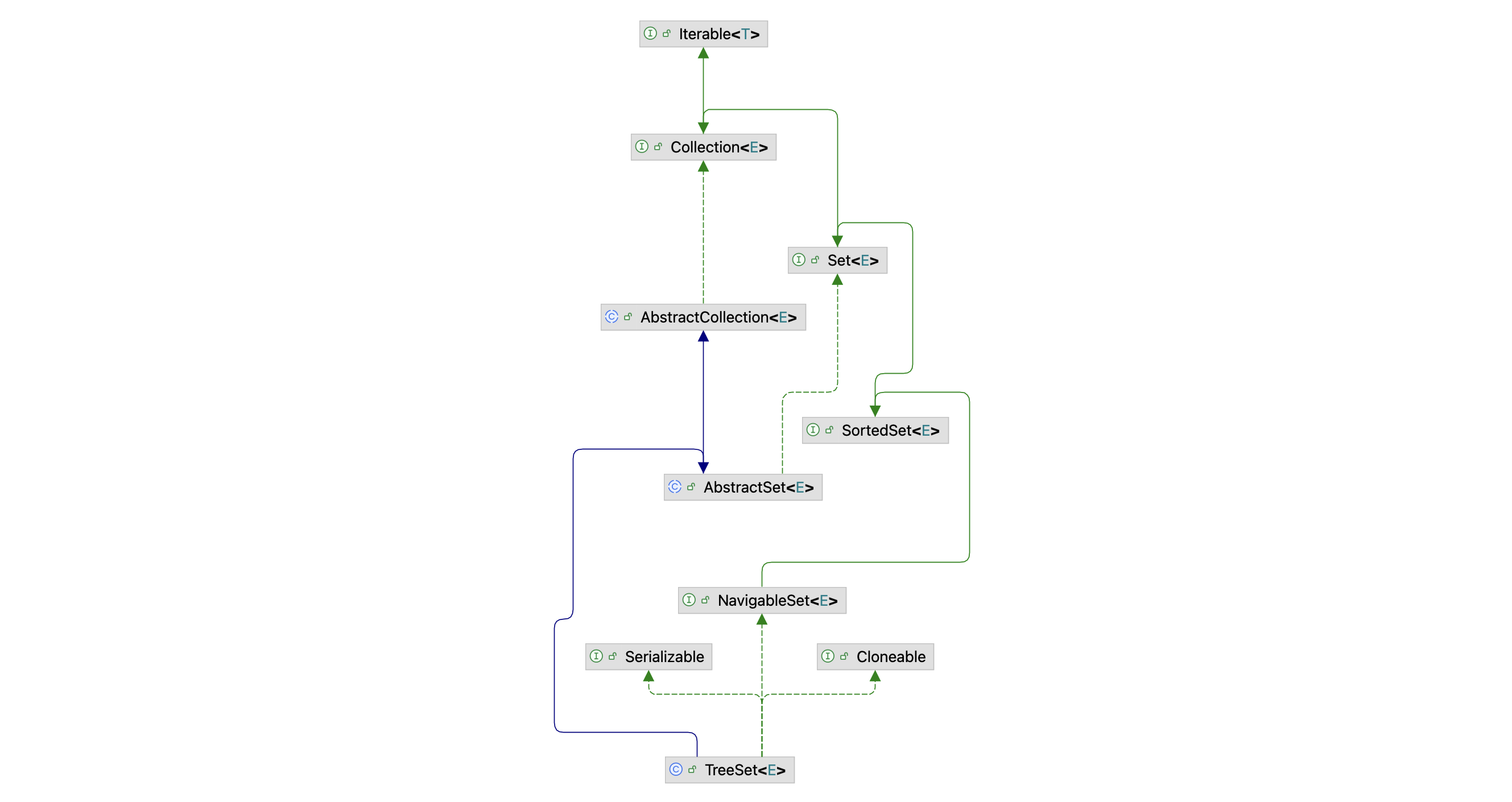
图 TreeSet 类的继承关系
红黑树是一种特殊的二叉查找树,它满足以下性质:
- 节点颜色:每个节点要么是红色,要么是黑色。
- 根节点:根节点必须是黑色。
- 叶节点:叶节点(NIL 或空节点)都是黑色。
- 红色节点的子节点:如果一个节点是红色的,则它的两个子节点都是黑色的(即不存在两个连续的红色节点)。
- 路径上黑色节点的数量:从任一节点到其每个叶节点的所有简单路径都包含相同数目的黑色节点。
这些性质确保了红黑树的平衡性,从而在插入、删除和查找等操作中保持对数时间复杂度 O(log n),其中 n 是树中的节点数。
数据结构
TreeSet 的底层实现依赖于 TreeMap。TreeSet 内部维护了一个 NavigableMap(实际上是 TreeMap 的实例)来存储元素。TreeMap 的键是 TreeSet 中的元素,而值是一个固定的对象(通常是一个静态常量,如 PRESENT),因为 TreeSet 只关心键(即元素本身),而不关心值。
- 成员变量:TreeSet 中有一个
NavigableMap<E, Object>类型的成员变量m,用于存储元素。还有一个静态常量PRESENT,作为 TreeMap 中值的占位符。

图 TreeSet 类中所有的属性
- 构造函数:
TreeSet():创建一个空的 TreeSet,使用元素的自然顺序进行排序。如果元素没有实现 Comparable 接口,将抛出ClassCastException。TreeSet(Comparator<? super E> comparator):创建一个空的 TreeSet,使用指定的 Comparator 进行排序。TreeSet(Collection<? extends E> c):创建一个包含指定集合中元素的 TreeSet,按照元素的自然顺序排序。TreeSet(SortedSet<E> s):创建一个包含与指定排序集相同元素和相同排序方式的 TreeSet。
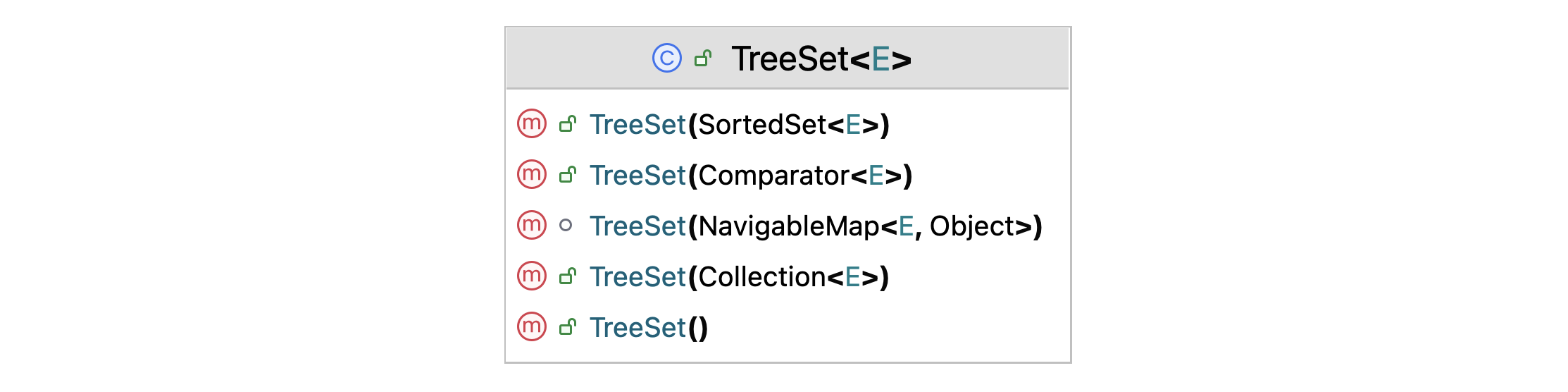
图 TreeSet 类中提供的构造方法
添加元素
调用 TreeSet 的 add(E e) 方法可以添加元素:
- 当向 TreeSet 中添加元素时,实际上是调用了 TreeMap 的
put方法,将元素作为键,PRESENT作为值添加到 TreeMap 中。 - 如果元素已经存在于 TreeSet 中(即 TreeMap 中已存在相同的键),则不会添加该元素,保证了元素的唯一性。
- 添加元素时,红黑树的性质会被维护,确保树的平衡性。
TreeSet 的 add(E e) 方法实现如下:
java
/**
* 如果指定元素不存在,则将该元素添加到此集合。
* 更正式地说,如果该集合不包含元素 e2,则向该集合添加指定元素 e,使得 e==null ? e2==null : e.equals(e2)
* 如果该集合已经包含该元素,则调用保持集合不变并返回 false。
*
* @param e 要添加到此集合的元素
* @return 如果此集合尚未包含指定的元素,则返回 true
* @throws ClassCastException 如果指定的对象不能与当前在此集合中的元素进行比较
* @throws NullPointerException 如果指定的元素为空且此集合使用自然排序,或者其比较器不允许为空元素
*/
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}TreeMap 的 put(K key, V value) 方法具体实现如下:
java
/**
* 将指定值与此映射中的指定键关联。
* 如果映射以前包含键的映射,则替换旧值。
*
* @param key 要与指定值相关联的键
* @param value 值,以便与指定的键关联
*
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}.
* (A {@code null} return can also indicate that the map
* previously associated {@code null} with {@code key}.)
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key is null
* and this map uses natural ordering, or its comparator
* does not permit null keys
*/
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}删除元素
调用 TreeSet 的 remove(Object o) 方法删除元素:
- 删除元素时,调用 TreeMap 的
remove方法,移除指定的键(元素)。 - 如果键存在,则删除成功;否则,删除操作无效。
TreeSet 的 remove(Object o) 方法实现如下:
java
/**
* 如果指定元素存在,则从该集合中删除指定元素。
* 更正式地,如果这个集合包含这样一个符合条件的元素 o == null ? e == null : o.equals(e),则移除这个元素。
* 如果此集合包含该元素,则返回 true(或者等价地,如果此集合因调用而更改),一旦调用返回,这个集合将不包含该元素。
*
* @param o 对象,如果存在,则从该集合中删除
* @return true 如果集合包含指定的元素
* @throws ClassCastException 如果指定的对象不能与当前在此集合中的元素进行比较
* @throws NullPointerException 如果指定的元素为空并且此集合使用自然排序,或者其比较器不允许为空元素
*/
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}TreeMap 的 remove(Object key) 方法实现如下:
java
/**
* 从此 TreeMap 中删除此键的映射(如果存在)。
*
* @param key key for which mapping should be removed
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}.
* (A {@code null} return can also indicate that the map
* previously associated {@code null} with {@code key}.)
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key is null
* and this map uses natural ordering, or its comparator
* does not permit null keys
*/
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}查找元素
调用 TreeSet 的 contains(Object o) 方法查找元素:
- 查找元素时,调用 TreeMap 的
containsKey方法,检查指定的键(元素)是否存在于 TreeMap 中。
TreeSet 的 contains(Object o) 方法实现如下:
java
/**
* 如果此集合包含指定的元素,则返回 true。
* 更正式地说,当且仅当此集合包含元素 e 使得 o == null ? e == null : o.equals(e) 时,才返回 true。
*
* @param o 要检查此集中是否包含的对象
* @return 如果此集合包含指定的元素,则为 true
* @throws ClassCastException 如果指定的对象不能与集合中的当前元素进行比较
* @throws NullPointerException 如果指定的元素为空并且此集合使用自然排序,或者其比较器不允许为空元素
*/
public boolean contains(Object o) {
return m.containsKey(o);
}实际上时使用了 TreeMap 的 containsKey(Object key) 方法:
java
/**
* 如果此映射包含指定键的映射,则返回 true。
*
* @param key 键
* @return true 如果此映射包含指定键的映射
* @throws ClassCastException 如果指定的键不能与映射中的当前键进行比较
* @throws NullPointerException 如果指定的键为空并且此映射使用自然排序,或者其比较器不允许空键
*/
public boolean containsKey(Object key) {
return getEntry(key) != null;
}getEntry(Object key) 方法的具体实现如下:
java
/**
* 返回给定键的映射项,如果映射不包含该键的项,则返回 null。
*
* @return 该映射为给定键的项,如果映射不包含该键的项,则为空
* @throws ClassCastException 如果指定的键不能与映射中的当前键进行比较
* @throws NullPointerException 如果指定的键为空并且此映射使用自然排序,或者其比较器不允许空键
*/
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}遍历元素
- TreeSet 提供了
iterator()方法,返回一个正序迭代器,按照元素的排序顺序遍历集合。java/** * 按升序返回遍历集合中元素的迭代器。 * * @return 按升序遍历该集合中的元素的迭代器 */ public Iterator<E> iterator() { return m.navigableKeySet().iterator(); } - 还提供了
descendingIterator()方法,返回一个逆序迭代器,按照与正序相反的顺序遍历集合。java/** * 按降序返回遍历集合中元素的迭代器。 * * @return 按降序遍历该集合中的元素的迭代器 * @since 1.6 */ public Iterator<E> descendingIterator() { return m.descendingKeySet().iterator(); }
总结
特点:
- 有序性:TreeSet 中的元素按照自然顺序或指定的 Comparator 排序,保证了元素的有序性。
- 唯一性:TreeSet 不允许存储重复的元素。
- 动态平衡:红黑树的自平衡特性保证了 TreeSet 在插入、删除和查找操作中的高效性。
- 导航方法:作为 NavigableSet 的实现,TreeSet 提供了丰富的导航方法,如查找最小元素、最大元素、子集等。
LinkedHashSet
LinkedHashSet 继承自 HashSet 并实现了 Set 接口。与 HashSet 不同,LinkedHashSet 保证了元素的插入顺序,即迭代时元素的顺序与插入时的顺序一致。LinkedHashSet 的底层数据结构设计独特,结合了哈希表和链表的优点。
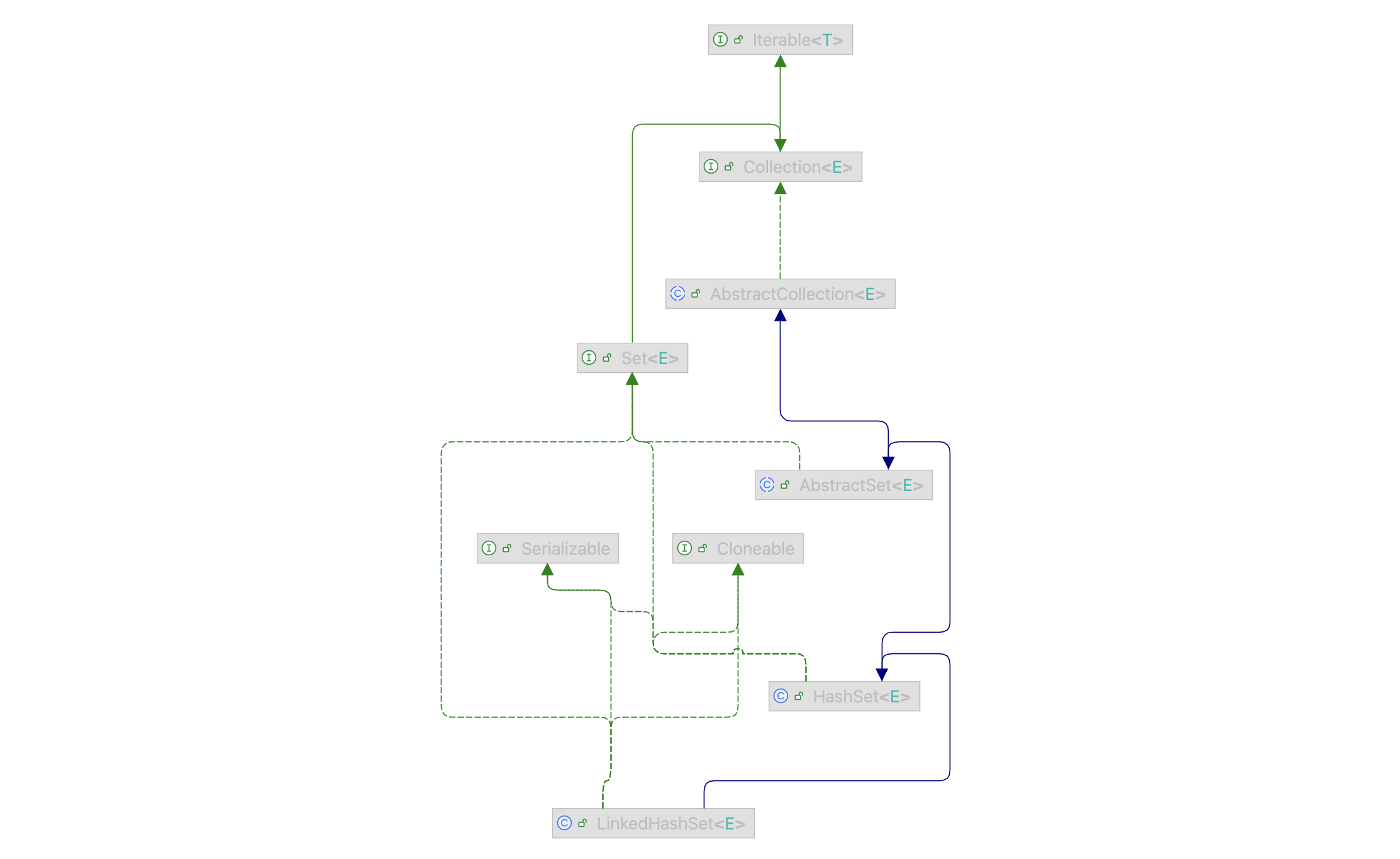
图 LinkedHashSet 类的继承关系
数据结构
LinkedHashSet 的底层数据结构实际上是一个 LinkedHashMap。LinkedHashMap 是 HashMap 的一个子类,它在 HashMap 的基础上增加了一个双向链表,用于维护元素的插入顺序。因此,LinkedHashSet 的底层可以看作是“数组 + 双向链表”的结构。
- 数组:LinkedHashMap(也是 LinkedHashSet)内部维护了一个数组(HashMap 中的 table 数组),用于存储桶(Buckets)。每个桶内部可以存储多个 Entry 对象,这些 Entry 对象通过链表或红黑树连接,以解决哈希冲突。
- 双向链表:LinkedHashMap 中的每个 Entry 对象都维护了 before 和 after 两个指针,用于形成双向链表。这个双向链表保证了元素的插入顺序,使得 LinkedHashSet 在迭代时能够按照元素的插入顺序进行遍历。
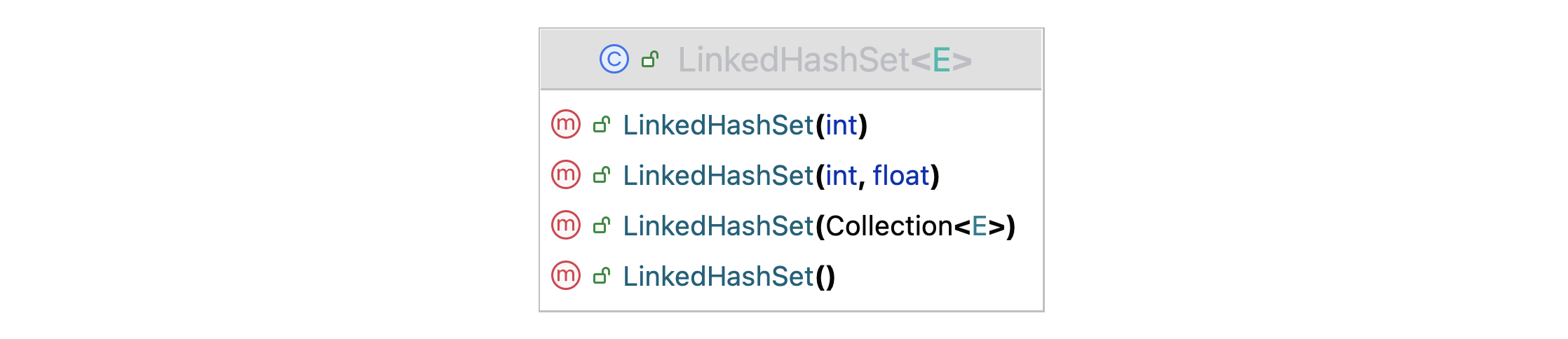
图 LinkedHashSet 类中提供的构造方法
添加元素
- 当向 LinkedHashSet 中添加元素时,首先计算元素的哈希码(通过调用元素的
hashCode()方法),然后根据哈希码和数组的长度确定元素在数组中的索引位置。 - 如果该索引位置已经存在元素,则处理哈希冲突(通常是通过链表或红黑树将新元素添加到链表的末尾或红黑树的适当位置)。
- 同时,新元素会被添加到双向链表的末尾,以保持元素的插入顺序。
查找元素
- 查找元素时,首先计算元素的哈希码,然后根据哈希码和数组的长度确定元素在数组中的索引位置。
- 遍历该索引位置对应的链表或红黑树,查找具有相同哈希码和
equals方法相等的元素。 - 由于 LinkedHashMap 的链表或红黑树结构,查找操作的时间复杂度为 O(1)(平均情况下)或 O(log n)(最坏情况下,当链表转换为红黑树时)。
删除元素
- 删除元素时,首先计算元素的哈希码,然后根据哈希码和数组的长度确定元素在数组中的索引位置。
- 遍历该索引位置对应的链表或红黑树,找到要删除的元素。
- 从链表或红黑树中移除该元素,并更新双向链表的指针,以保持链表的完整性。
遍历元素
- LinkedHashSet 提供了迭代器(Iterator),用于按插入顺序遍历集合中的元素。
- 迭代器通过遍历双向链表来实现元素的顺序访问。
总结
特点:
- 查找、添加和删除操作:由于 LinkedHashSet 底层使用了 HashMap(实际上是 LinkedHashMap),因此它具有常数时间复杂度的查找、添加和删除操作(平均情况下)。然而,在最坏情况下(当链表转换为红黑树时),某些操作的时间复杂度可能上升为 O(log n)。
- 内存开销:与 HashSet 相比,LinkedHashSet 需要额外的内存来维护双向链表,因此其内存开销相对较大。
- 线程安全:LinkedHashSet 是非线程安全的。如果需要在多线程环境下使用,需要额外的同步机制。
LinkedHashSet 适用于需要保持元素插入顺序的场景,例如:
- LRU 缓存:最近最少使用(Least Recently Used)缓存策略中,可以使用 LinkedHashSet 来维护一个固定大小的缓存集合,按照元素的访问顺序进行淘汰。
- 任务调度:在任务调度系统中,可以使用 LinkedHashSet 来维护一个任务队列,按照任务的提交顺序进行调度。
- 用户会话管理:在用户会话管理系统中,可以使用 LinkedHashSet 来维护一个用户会话集合,按照用户的登录顺序进行管理。